Set 컬렉션 - TreeSet(개념)
Set 컬렉션 - TreeSet (개념)
TreeSet은 Set 인터페이스를 구현한 컬렉션 클래스이며, 이진 검색 트리(binary search tree)라는 자료구조의 형태로 데이터를 저장한다.
이진 검색 트리는 검색, 범위 검색, 정렬에 높은 성능을 제공하는 자료구조이며, TreeSet은 이진 검색 트리의 성능에서 향상된 '레드-블랙 트리(Red-Black tree)로 구현되어 있다.
*참고* 이진 검색 트리의 성능을 향상시키기 위해 여러 가지 변형과 최적화된 자료 구조가 개발되었다. 향상된 자료 구조는 특정 작업에서 더 빠른 속도와 효율성을 제공하며, 시간 복잡도 문제를 완화해준다. 이처럼 향상된 이진 검색 트리 중에 TreeSet은 트리의 높이를 최소화하는 데 중점을 둔 구조인 '균형 이진 검색 트리(Balanced Binary Search Tree)'의 레드- 블랙 트리를 기반으로 구현했다.
TreeSet은 Set인터페이스의 특성처럼 저장 순서를 유지하지 않고 중복을 허용하지 않는다. 이진트리는 계층적인 구조로 여러 개의 노드가 서로 연결된 형태로 구성되어 있으며, 각 노드가 최대 2개의 자식만 가질 수 있는 트리 구조를 말한다.
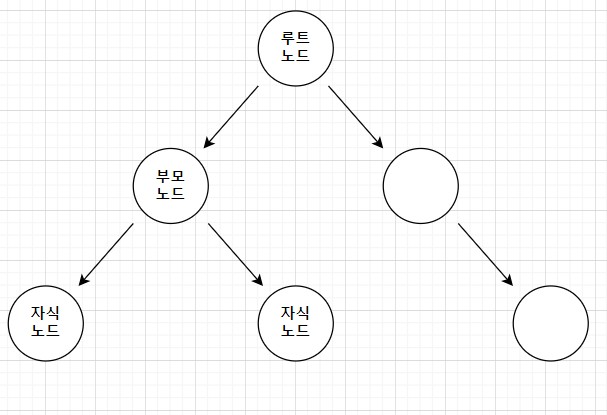
이진 트리 노드의 구성
| 노드(Node) - 트리를 구성하는 각 요소(원소)를 나타내는 기본 단위 - 각 노드는 최대 두 개의 자식 노드를 가질 수 있다 |
| 루트 노드(Root Node) - 트리의 맨 꼭대기에 위치한 노드, 즉 최상위 노드 |
| 자식 노드(Child Node) - 루트 노드를 제외한 모든 노드라고 말할 수 있으며, 이진트리에서 왼쪽 자식 노드와 오른쪽 자식 노드로 분류된다. |
| 잎 노드(Leaf Node) - 자식 노드가 없는 최하위 노드이며, 잎 노드 또는 말단 노드라고 표현한다. |
이진 트리의 노드를 코드로 표현하면 다음과 같다.
class TreeNode{
TreeNode left; // 왼쪽 자식 노드
Object element; // 객체를 저장하기 위한 참조변수
TreeNode right; // 오른쪽 자식 노드
}위 코드는 데이터를 저장하기 위한 Object 타입 참조변수와 두 개의 자식노드를 참조하기 위한 참조변수를 선언했다.
이진 검색 트리는 부모노드 기준으로 왼쪽에는 부모의 값보다 작은 값을 가진 자식 노드를, 오른쪽에는 큰 값의 자식노드를 저장하는 이진 트리이다.
그림으로 표현하면 다음과 같은 구조로 나타난다

저장 방식을 보다 자세하게 이해하기 위해 이진 검색트리에 7, 15, 6, 4, 16의 순서로 값을 저장한다고 가정하면 다음과 같은 순서로 저장된다.

첫 번째로 저장되는 값이 루트가 되고, 그 다음 노드부터는 부모 노드를 기준으로 값의 크기를 비교하면서 트리를 따라 내려 간다. 작은 값은 왼쪽에, 그리고 큰 값은 오른쪽에 저장한다.
이러한 방식으로 트리를 구성하면, 왼쪽 마지막 레벨의 잎노드는 가장 작은 값이 될 것이고 오른쪽 마지막 레벨의 값은 제일 큰 값이 될 것이다.
이 순서도를 분석해보면, '왼쪽 노드 -> 부모 노드 -> 오른쪽 노드' 순으로 읽어보면 쉽게 오름차순으로 정렬된 순서를 알 수 있다.
TreeSet은 이와 같이 정렬된 상태를 유지하므로 단일 값 검색과 범위 검색의 속도가 매우 빠르다. 예를 들어, 노드의 표현 범위는 1~100이고 루트 노드가 50, 탐색하고자 하는 값이 50보다 작은 값이라고 가정해보자. 그렇다면, 루트 노드의 오른쪽은 50보다 큰 값인 것을 이미 알기 때문에 오른쪽 노드는 탐색할 것도 없이 왼쪽 노드를 순회해서 단 몇번의 비교만으로 빠르게 탐색할 수 있을 것이다.
물론 저장된 값의 개수가 많을수록 검색시간이 증가하긴 하지만 값의 개수가 몇배는 증가한다고 해도, 특정 값을 찾는데 필요한 비교 횟수가 몇번 안될 정도로 검색 효율이 뛰어난 자료구조이다.
그러나, Set 컬렉션의 특성상 데이터를 순차적으로 저장하는 것이 아니라 저장위치를 탐색해서 저장해야하고, 데이터의 삭제가 필요한 경우 트리의 일부를 재구성해야하기 때문에 삽입, 삭제에 대한 시간 비용이 LinkedList에 비해 비교적 크지만 배열이나 List 컬렉션에 비해 검색과 정렬 성능이 훨씬 뛰어나다.
정리
이진 검색 트리
- 모든 노드는 최대 두 개의 자식 노드를 가질 수 있다.
- 정렬 방식은 부모 노드 기준으로 왼쪽 노드는 작은 값을, 오른쪽 노드는 큰 값을 갖는다.
- 데이터가 순차적으로 저장되지 않기 때문에 노드의 삽입, 삭제에는 시간 비용이 다른 자료구조에 비해 클 수 있다.
- 범위검색과 정렬에 유리한 자료 구조이다.
- 중복된 값은 허용하지 않는다.