LinkedList에 대한 이해
배열은 가장 기본적인 형태의 자료구조로, 사용법이 쉽고 데이터의 접근 속도가 빠르다는 장점이 있지만 다음과 같은 단점이 있다.
고정적 크기
- 한번 크기를 지정하면 변경할 수가 없어, 새로운 배열을 생성해서 데이터를 복사해야 하는 번거로움이 있다.
- 빠른 접근속도를 위해서 충분한 크기의 배열을 만들어야 하므로 메모리가 낭비 될 수 있다.
데이터 추가 및 삭제
- 순차적으로 데이터를 추가하고 끝에서부터 데이터를 삭제하는 것은 빠르지만, 중간에 데이터를 추가하거나 삭제를 하는 경우, 이를 위해 요소 간 이동을 하는 시간 비용이 크다.
이러한 배열의 단점을 보완하기 위해서 연결 리스트가 고안되었다.
이 자료구조의 특징은 불연속적으로 존재하는 데이터를 서로 연결한 형태로 설계한 것이다.
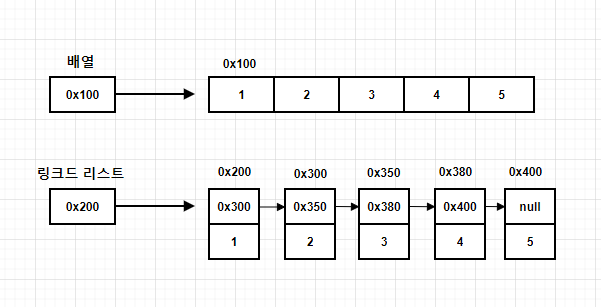
연결 리스트 (Singly Linked List)
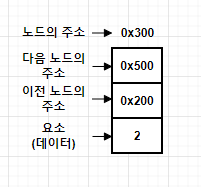
연결 리스트는 요소를 노드로 구성하여 연결된 방식(link)으로 데이터를 저장하는 것이 특징이다. 각 노드는 데이터 요소와 그 다음 노드의 주소 값을 가리키는 참조로 이루어져 있다.
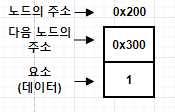
연결 리스트의 가장 큰 장점 중 하나는, 데이터의 추가나 삭제가 발생할 때 요소 간의 이동이 필요없고 방법이 간단하다는 것이다.
데이터의 삭제
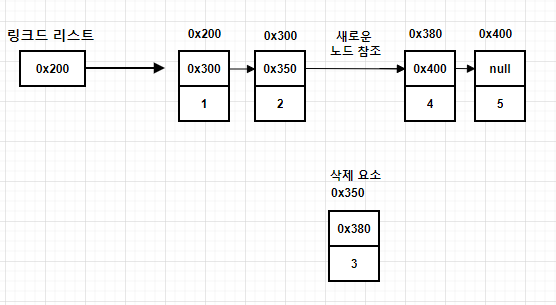
삭제의 경우, 아래 그림과 같이 삭제하고자 하는 요소의 '이전 요소(0x300)'가 삭제 요소(0x350)의 '다음 요소(0x380)'를 참조하도록 변경만 하면 된다. 즉, 단 하나(이전 요소)의 참조만 변경되면 삭제가 이루어지는 것이다.
데이터의 삽입
데이터 삽입도 마찬가지로 아래 그림과 같이 새로운 요소를 생성한 다음, 원하는 '이전 요소(0x300)를 '새로운 요소(0x500)'에 참조하도록 변경하고, '새로운 요소(0x500)'를 '다음 요소(0x380)'를 참조하도록 변경한다.
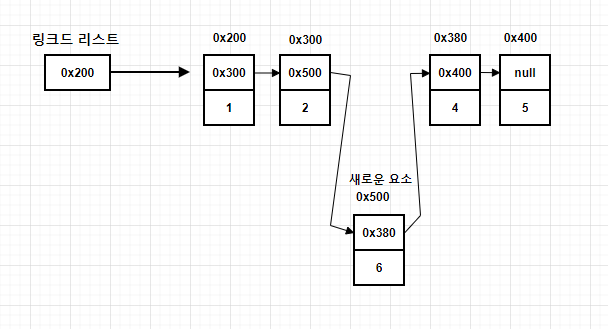
정리하자면, 연결 리스트는 데이터를 중간에 삽입하거나 삭제할 때 이전 노드 또는 새로운 노드의 참조 값만 조정하면 되므로, 추가 및 삭제가 자주 발생할 가능성이 있는 데이터 집합에서 유용하다.
그러나,연결 리스트는 이동방향이 단방향이기 때문에 순회할 때는 다음 노드에 대한 접근은 쉽지만 이전 노드에 대한 접근이 어렵다. 따라서, 이 점을 보완하기 위해 이중 연결 리스트(Doubly Linked List)가 고안되었다.
이중 연결 리스트(Doubly Linked List, 양방향)
이중 연결 리스트는 단순히 단방향 연결 리스트에서 이전 노드에 대한 참조가 가능하도록 참조변수만 하나 더 추가된 형태이며, 그 외에는 연결 리스트와 동일하다.
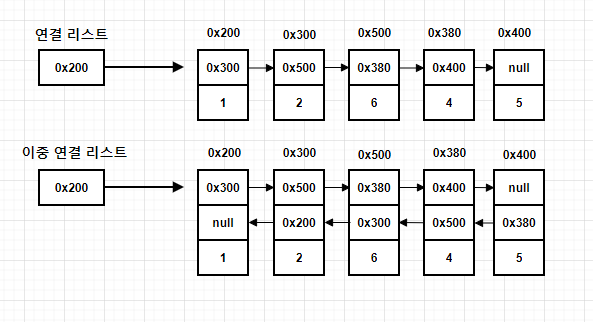
이중 연결 리스트는 각 요소에 대한 접근과 이동이 쉽기 때문에 일반적으로 단방향 연결 리스트보다 더 많이 사용된다.
이중 원형 연결 리스트(doubly circular linked list)
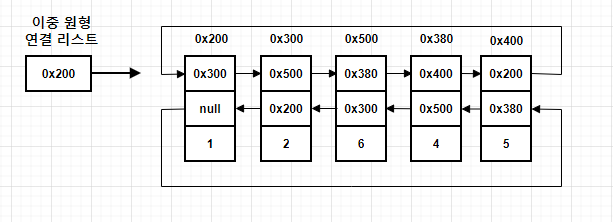
그러나, 이중 연결 리스트에도 아쉬운 점이 있다. 첫 번째에서 마지막까지 또는 마지막에서 첫 번째까지 가려면 그 사이 모든 노드를 거쳐야 한다는 것이다.
따라서, 접근성을 최대한 향상하고자 제안된 것이 이중 원형 연결리스트(doubly circular linked list)이다.
위 그림에서 알 수 있듯이, 첫 번째 노드의 이전 참조 값과 마지막 노드의 다음 참조 값이 null인 것을 확인할 수 있다. 이를 최대한 활용하고자 첫 번째 노드의 이전 참조 값은 마지막 노드를, 마지막 노드의 다음 참조 값은 첫 번째 노드를 참조한 형태가 이중 원형 연결리스트이다.
LinkedList 클래스
List 인터페이스를 구현한 LinkedList 클래스에서는 실제로 '이중 연결 리스트'로 구현되어 있다. LinkedList는 java.util 패키지에 속해 있으며, 활용 예시는 다음과 같다.
LinkedList<> li = new LinkedList<>(); // LinkedList 선언
li.add("요소 추가"); // 요소 추가
li.contains("요소 추가"); // 요소 포함 여부를 boolean으로 반환
li.get(0); // n번 인덱스의 요소를 반환
li.remove(0); // n번 인데스 위치의 요소를 반환 후 제거
*참고* LinkedList 또한 List인터페이스를 구현했기 때문에 ArrayList와 내부 구현 방법만 다르고 메서드의 종류와 기능은 거의 유사하다.
✅ 1. 요소 추가 (add(), addFirst(), addLast())
| 메서드 | 설명 |
| boolean add(E e) | 리스트의 끝에 요소 e 추가. |
| void add(int index, E element) | 특정 index 위치에 요소 element 추가. |
| boolean addAll(Collection<? extends E> c) | 리스트의 끝에 컬렉션 c의 모든 요소를 추가. |
| boolean addAll(int index, Collection<? extends E> c) | 특정 index 위치에 컬렉션 c의 모든 요소를 삽입. |
| void addFirst(E e) | 리스트의 첫 번째 위치에 요소 추가. |
| void addLast(E e) | 리스트의 마지막 위치에 요소 추가. |
✅ 2. 요소 접근 및 검색 (get(), getFirst(), getLast())
| 메서드 | 설명 |
| E get(int index) | 특정 index 위치의 요소를 반환. |
| E getFirst() | 리스트의 첫 번째 요소를 반환. |
| E getLast() | 리스트의 마지막 요소를 반환. |
| int indexOf(Object o) | 리스트에서 처음으로 나타나는 요소 o의 위치를 반환. |
| int lastIndexOf(Object o) | 리스트에서 마지막으로 나타나는 요소 o의 위치를 반환. |
| boolean contains(Object o) | 리스트가 특정 요소 o를 포함하고 있는지 확인. |
✅ 3. 요소 수정 (set())
| 메서드 | 설명 |
| E set(int index, E element) | 특정 index 위치의 요소를 element로 변경. |
✅ 4. 요소 제거 (remove(), removeFirst(), removeLast())
| 메서드 | 설명 |
| E remove(int index) | 특정 index 위치의 요소를 제거하고 반환. |
| boolean remove(Object o) | 리스트에서 처음 발견되는 요소 o를 제거. |
| E removeFirst() | 리스트의 첫 번째 요소를 제거하고 반환. |
| E removeLast() | 리스트의 마지막 요소를 제거하고 반환. |
| boolean removeAll(Collection<?> c) | 리스트에서 컬렉션 c의 모든 요소를 제거. |
| void clear() | 리스트의 모든 요소를 제거. |
✅ 5. 리스트 크기 및 상태 확인 (size(), isEmpty())
| 메서드 | 설명 |
| int size() | 리스트의 요소 개수를 반환. |
| boolean isEmpty() | 리스트가 비어 있는지 확인. |
✅ 6. 리스트 변환 (toArray())
| 메서드 | 설명 |
| Object[] toArray() | 리스트의 모든 요소를 포함하는 Object[] 배열 반환. |
| <T> T[] toArray(T[] a) | 리스트의 요소를 지정된 타입의 배열 a로 변환하여 반환. |
✅ 7. 리스트 정렬 (sort())
| 메서드 | 설명 |
| void sort(Comparator<? super E> c) | 리스트를 주어진 Comparator에 따라 정렬. |
✅ 8. 큐(Queue) 기능 (offer(), poll(), peek())
| 메서드 | 설명 |
| boolean offer(E e) | 리스트의 끝에 요소 추가 (add()와 유사). |
| E poll() | 리스트의 첫 번째 요소를 제거하고 반환 (removeFirst()와 유사). |
| E peek() | 리스트의 첫 번째 요소를 반환하지만 제거하지 않음 (getFirst()와 유사). |
✅ 9. 스택(Stack) 기능 (push(), pop())
| 메서드 | 설명 |
| void push(E e) | 리스트의 첫 번째 위치에 요소 추가 (addFirst()와 유사). |
| E pop() | 리스트의 첫 번째 요소를 제거하고 반환 (removeFirst()와 유사). |
✅ 10. 부분 리스트 반환 (subList())
| 메서드 | 설명 |
| List<E> subList(int fromIndex, int toIndex) | 리스트의 fromIndex부터 toIndex 이전까지의 부분 리스트 반환. |
✅ 11. 리스트 반복자 (iterator(), listIterator())
| 메서드 | 설명 |
| Iterator<E> iterator() | 리스트를 순회할 수 있는 Iterator 반환. |
| ListIterator<E> listIterator() | 리스트를 순회할 수 있는 ListIterator 반환. |
| ListIterator<E> listIterator(int index) | 특정 index 위치에서 시작하는 ListIterator 반환. |
아래는 ArrayList와 LinkedList의 장단점을 비교한 표이다. 데이터의 추가 삭제가 잘 변하지 않는 데이터 구조로는 ArrayList가 좋은 선택일 것이고, 변경이 빈번할 경우에는 LinkedList를 사용하는 것이 더 나은 선택이 될 것이다.
ArrayList와 LinkedList의 비교
| 컬렉션 | 읽기(접근시간 | 추가/삭제 | 비고 |
| ArrayList | 빠르다 | 느리다 | 순차적인 추가삭제는 더 빠름 비효율적인 메모리 사용 |
| LinkedList | 느리다 | 빠르다 | 데이터가 많을수록 접근이 떨어진다. |
'Java > 컬렉션 프레임워크' 카테고리의 다른 글
| Set 컬렉션 - TreeSet(개념) (0) | 2023.09.06 |
|---|---|
| List 컬렉션, ArrayList (0) | 2023.09.02 |
| List, Set, Map 인터페이스 (0) | 2023.08.27 |
| 컬렉션 프레임워크 (0) | 2023.08.27 |

